
База данных (БД) - это организованная структура, предназначенная для хранения, изменения и обработки информации. Это структурированное хранилище данных.
Какие типы БД знаешь?
Реляционные (SQL)
Характерны тем, что данные могут быть связанными между собой с помощью отношений (relation - связь, отношение), например - значение одной колонки может ссылаться на какую-либо колонку в другой таблице (aka “внешние ключи”). Данные хранятся в виде набора таблиц, состоящих из столбцов и строк. В каждом столбце (column) хранятся данные определенного типа.
Схема таблиц объявляется при её создании.
Примеры: MySQL (C++) (или её форк MariaDB), PostgreSQL (C), SQLite (C)
Нереляционные (NoSQL)
NoSQL - Not Only Structured Query Language
Обладают гибкими схемами, т.е. объявлять структуру помещаемых данных заранее часто не является обязательным условием.
Key/Value
Хранилища предоставляют доступ к данным, которые хранятся по уникальным ключам в “плоском” представлении. Чтобы запросить данные, нужно знать их ключ. Часто используется хранение данных в виде JSON-объектов, но для СУБД это просто некоторый случайный набор байт (blob-объект).
Примеры: Redis (C), KeyDB (C++), memcached (C), etcd (Go)
Документные (документ-ориентированные)
Используют базовую семантику доступа и поиска хранилищ ключей и значений, часто имеют структуру дерева (иногда леса). Такие БД также используют ключ для уникальной идентификации данных. Разница между хранилищами “Key/Value” и документными БД заключается в том, что вместо хранения blob-объектов, документ-ориентированные базы хранят данные в структурированных форматах – JSON, BSON или XML.
Как следствие:
- Документы могут быть организованы (сгруппированы) в коллекции (их можно считать отдалённым аналогом таблиц реляционных СУБД)
- База данных не предписывает определенный формат или схему
- Каждый документ может иметь свою внутреннюю структуру
- Документные БД являются хорошим выбором для быстрой разработки
- В любой момент можно менять свойства данных, не изменяя структуру или сами данные
Примеры: MongoDB (C++), RethinkDB (C++), Elasticsearch (Java), Aerospike (C)
Колоночные
Внешне похожи на реляционные БД (хранят данные, используя строки и столбцы), но с иной связью между элементами. Данные группируются не по строкам, а по столбцам. В ней “соседними” являются не данные из двух столбцов одной и той же строки, а данные из одного и того же столбца, но из разных строк.
Особенностью является высокая скорость и гибкость выполнения сложных запросов. Действительно, в “строчной” СУБД при поиске и считывании значений сканируется вся таблица по строкам и столбцам, а затем извлекаются строки целиком, даже в том случае, если нужно только одно значение каждой из них. Колоночные базы данных позволяют искать значения по отдельным столбцам и извлекать только те значения, которые требуются.
Примеры: ClickHouse (C++), Cassandra (Java)
Графовые
Вместо сопоставления связей с таблицами и внешними ключами, графовые базы данных устанавливают связи, используя узлы, рёбра и свойства. Они представляют данные в виде отдельных узлов, которые могут иметь любое количество связанных с ними свойств.
Примеры: Neo4j (Java), Dgraph (Go), RedisGraph (C)
Time series (временны́х рядов)
Созданы для сбора и управления элементами, меняющимися с течением времени. Большинство таких БД организованы в структуры, которые записывают значения для одного элемента (например, временная метка и значение температуры процессора). В таблице может быть несколько метрик. Оптимизированы для быстрой записи данных.
Примеры: Prometheus (Go), InfluxDB (Go)
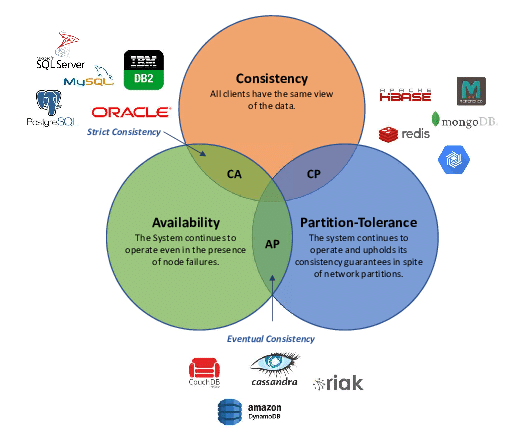
Что такое CAP-теорема (теорема Брюера)?
Утверждение о том, что в любой реализации распределённых вычислений возможно обеспечить не более двух из трёх следующих свойств:
- Согласованность данных (
consistency) - как только мы успешно записали данные в наше распределенное хранилище, любой клиент при запросе получит эти последние данные - Доступность (
availability) - в любой момент клиент может получить данные из нашего хранилища, или получить ответ об их отсутствии, если их никто еще не сохранял - Устойчивость к разделению (
partition tolerance) - потеря сообщений между компонентами системы (возможно даже потеря всех сообщений) не влияет на работоспособность системы
С точки зрения теоремы CAP, распределённые системы в зависимости от пары практически поддерживаемых свойств из трёх возможных распадаются на три класса:
- CA (
consistency + availability) - во всех узлах данные согласованы и обеспечена доступность, при этом она жертвует устойчивостью к распаду на секции - CP (
consistency + partition tolerance) - в каждый момент обеспечивает целостный результат и способна функционировать в условиях распада, но достигает этого в ущерб доступности - может не выдавать отклик на запрос - AP (
availability + partition tolerance) - не гарантируется целостность, но при этом выполнены условия доступности и устойчивости к распаду на секции
Что можно почитать:
Что такое свойство ACID в базе данных?
ACID используется для обеспечения надежной обработки транзакций данных в СУБД и означает:
- Атомарность (
Atomicity) - гарантирует, что транзакция будет полностью выполнена или потерпит неудачу, где транзакция представляет одну логическую операцию данных (“всё или ничего”) - Согласованность или консистентность (
Consistency) - гарантирует, что данные должны соответствовать всем правилам валидации - Изолированность (
Isolation) - контроль механизма параллельного изменения данных - Долговечность или стойкость (
Durability) - если транзакция была подтверждена (COMMIT), произошедшие в рамках транзакции изменения сохранятся независимо от того, что может встать у них на пути (например, потеря питания, сбой или ошибки любого рода)
В базах данных, следующих принципу ACID, данные остаются целостными и консистентными, несмотря на любые ошибки.
NoSQL базы данных часто предназначены для обеспечения высокой доступности в кластере, а обычно это означает, что в некоторой степени жертвуют согласованностью (consistency) и/или стойкостью (durability). Хотя, разработчики такие как MarkLogic, OrientDB и Neo4j предлагают ACID-совместимые СУБД.
Вопросы по SQL
Из каких подмножеств состоит SQL?
- DDL (
Data Definition Language, язык описания данных) -позволяет выполнять различные операции с базой данных, такие какCREATE(создание),ALTER(изменение) иDROP(удаление объектов) - DML (
Data Manipulation Language, язык управления данными) -позволяет получать доступ к данным и манипулировать ими, например, вставлятьINSERT, обновлятьUPDATE, удалятьDELETEи извлекать данныеSELECTиз базы данных - DCL (
Data Control Language, язык контролирования данных) -позволяет контролировать доступ к базе данных; примеры -GRANT(предоставить права),REVOKE(отозвать права)
Что подразумевается под таблицей и полем в SQL?
Таблица - организованный набор данных в виде строк и столбцов. Поле - это столбцы в таблице.
В чем разница между операторами DELETE и TRUNCATE?
Deleteудаляет строку в таблице, аtruncateудаляет все строки- После
deleteвозможно откатить изменения, а послеtruncateкак правило нет Truncateработает быстрее
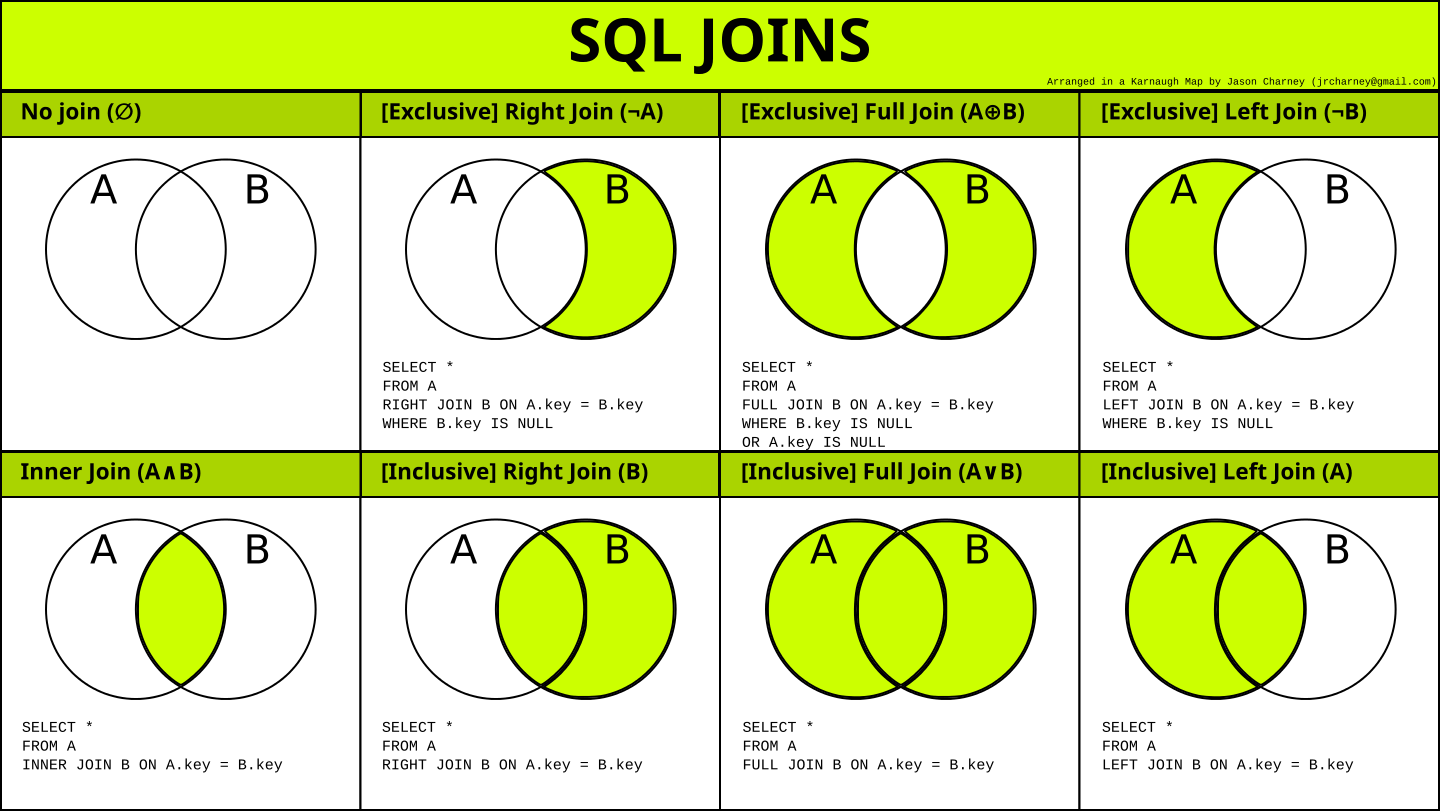
Что такое соединения (JOIN) в SQL?
Это объединение строк из двух (или более) таблиц на основе связанного между ними столбца. Примеры JOIN-ов:
INNER JOIN(внутреннее соединение) - пересечение двух таблиц, то есть строки, общие для каждой из них (пример:select * from a INNER JOIN b on a.a = b.b;)LEFT JOIN(левое соединение) - все строки из первой (левой) таблицы плюс все строки второй таблицы, имеющие совпадение со строками из первой таблицы (пример:select * from a LEFT OUTER JOIN b on a.a = b.b;)RIGHT JOIN(правое соединение) - все строки из второй (правой) таблицы плюс все строки первой таблицы, имеющие совпадение со строками из второй таблицы (пример:select * from a RIGHT OUTER JOIN b on a.a = b.b;)FULL JOIN(полное соединение) - полное соединение обеих таблиц (т.е. все строки из первой и второй таблиц); если соответствия нет, то значениеnull(пример:select * from a FULL OUTER JOIN b on a.a = b.b;)
Что можно почитать:
В чем разница между типом данных CHAR и VARCHAR в SQL?
И CHAR, и VARCHAR служат символьными типами данных, но VARCHAR используется для строк символов переменной длины, тогда как CHAR используется для строк фиксированной длины. Например, CHAR(10) может хранить только 10 символов и не сможет хранить строку любой другой длины, тогда как VARCHAR(10) может хранить строку любой длины до 10, т.е. например 6, 8 или 2.
Что такое первичный ключ (Primary key)?
Первичный ключ - столбец (или набор столбцов), которые однозначно идентифицируют каждую (одну) строку в таблице. Нулевые (null) значения не допускаются. Автоматически индексируются.
Что такое ограничения (Constraints)?
Ограничения (constraints) используются для указания ограничения на тип данных таблицы. Они могут быть указаны при создании или изменении таблицы. Пример ограничений:
NOT NULL- значение не может бытьnullCHECK- произвольные проверки на значение, напримерconstraint uuid_is_valid check (is_uuid(uuid))проверяет на валидность UUID идентификатор, аconstraint login_min_length check (char_length(login) >= 3)на минимальную длину строки поля логинаDEFAULT- устанавливает значение по умолчанию для поля в колонкеUNIQUE- обязывает значение бить уникальным в рамках таблицыPRIMARY KEY- объявляет первичный ключFOREIGN KEY- объявляет внешний ключ (связывает таблицы отношением), напримерconstraint user_uuid_foreign_key foreign key (user_uuid) references users (uuid) on update cascade on delete cascadeобязывает содержать значение вuser_uuidтолько для существующей записи в таблицеusersи автоматически обновится если оно будет изменено в таблицеusers, а так же заставит запись удалиться при удалении записи о пользователе
Что такое уникальный ключ (Unique key)?
Уникальный ключ однозначно идентифицирует одну строку в таблице (таблица не может содержать дубликатов). В одной таблице может быть несколько уникальных ключей. Возможны нулевые (null) значения.
Что такое внешний ключ (Foreign key)?
Внешний ключ поддерживает ссылочную целостность, обеспечивая связь между данными в двух таблицах. Внешний ключ в дочерней таблице ссылается на первичный ключ в родительской таблице. Ограничение внешнего ключа предотвращает действия, которые разрушают связи между дочерней и родительской таблицами.
Что подразумевается под целостностью данных?
Целостность данных определяет точность, а также согласованность данных, хранящихся в базе данных. Она также определяет ограничения целостности для обеспечения соблюдения бизнес-правил для данных, когда они вводятся в приложение или базу данных.
Например, вес детали должен быть положительным; количество знаков в телефонном номере не должно превышать 15; возраст родителей не может быть меньше возраста их биологического ребёнка и так далее.
Какие уровни изолированности транзакций можешь назвать?
Транзакция - это N (N≥1) запросов к БД, которые выполнятся успешно все вместе или не выполнятся вовсе. Изолированность же транзакции показывает то, насколько сильно влияют друг на друга параллельно выполняющиеся транзакции.
Read uncommitted(самая плохая согласованность данных, но самая высокая скорость выполнения) - каждая транзакция видит незафиксированные изменения другой транзакции (феномен “грязного чтения”). На данном уровне нельзя использовать данные, на основе которых делаются важные для приложения выводы и критические решенияRead committed(используется по умолчанию в PostgreSQL) - параллельно исполняющиеся транзакции видят только зафиксированные изменения из других транзакций (защита от “грязного чтения”). Т.е. для транзакции, работающей на этом уровне, запросSELECT(без предложенияFOR UPDATE/SHARE) видит только те данные, которые были зафиксированы до начала запроса; она никогда не увидит незафиксированных данных или изменений, внесённых в процессе выполнения запроса параллельными транзакциями. Этот уровень подвержен феномену неповторяющегося чтенияRepeatable read(используется по умолчанию в MySQL) - уровень, позволяющий предотвратить феномен неповторяющегося чтения. Т.е. мы не видим в исполняющейся транзакции измененные и удаленные записи другой транзакцией. Но все еще видим вставленные записи из другой транзакции. Чтение фантомов никуда не уходит.Serializable(самая низкая скорость выполнения и самая высокая согласованность) - транзакции ведут себя как будто ничего более не существует, никакого влияния друг на друга нет. В классическом представлении этот уровень избавляет от эффекта чтения фантомов
Что можно почитать:
Что вы подразумеваете под денормализацией?
Денормализация - техника, которая используется для преобразования из высших к низшим нормальным формам. Она помогает разработчикам баз данных повысить производительность всей инфраструктуры, поскольку вносит избыточность в таблицу. Она добавляет избыточные данные в таблицу, учитывая частые запросы к базе данных, которые объединяют данные из разных таблиц в одну таблицу.
Напишите SQL-запрос для отображения текущей даты?
Есть несколько способов (проверял на MySQL 8.0):
select CURDATE(); select CURRENT_DATEвернёт2022-03-16select NOW()вернёт2022-03-16 12:21:10, т.е. дату с текущим временемselect UNIX_TIMESTAMP()вернёт1647433317, т.е. временную метку в UNIX-формате
Индексы
Индекс создает отдельную структуру для индексируемого поля и, следовательно, позволяет быстрее получать данные (аналогично тому, как указатель в книге помогает вам быстро найти необходимую информацию).
В чем разница между кластеризованным и не кластеризованным индексами в SQL?
Различия между кластеризованным и не кластеризованным индексами в SQL:
- Кластеризованный индекс используется для простого и быстрого извлечения данных из базы данных, тогда как чтение из не кластеризованного индекса происходит относительно медленнее
- Кластеризованный индекс изменяет способ хранения записей в базе данных - он сортирует строки по столбцу, который установлен как кластеризованный индекс, тогда как в не кластеризованном индексе он не меняет способ хранения, но создает отдельный объект внутри таблицы, который указывает на исходные строки таблицы при поиске
- Одна таблица может иметь только один кластеризованный индекс, тогда как не кластеризованных у нее может быть много
Какие типы индексов знаешь?
PostgreSQL поддерживает несколько типов индексов: B-Tree, Hash, GiST, SP-GiST, GIN и BRIN. Для разных типов индексов применяются разные алгоритмы, ориентированные на определённые типы запросов. По умолчанию команда CREATE INDEX создаёт индексы типа B-Tree, эффективные в большинстве случаев.
B-Tree(self-balancing tree data structure) - хорошо работают в условиях на равенство и в проверках диапазонов с данными, которые можно отсортировать в некотором порядке (операторы<,<=,=,>=,>). Также оптимизатор может использовать индексы этого типа в запросах с операторами сравнения по шаблонуLIKEи~, если этот шаблон определяется константой и он привязан к началу строки - например,col LIKE 'foo%'илиcol ~ '^foo', но неcol LIKE '%bar'Hashхранят 32-битный хеш-код, полученный из значения индексированного столбца, поэтому хеш-индексы работают только с простыми условиями равенства=GiSTпредставляют собой не просто разновидность индексов, а инфраструктуру, позволяющую реализовать много разных стратегий индексирования. Применим для типов данныхbox,circle,inet,point,polygon,tsquery,tsvectorи диапазоны (для разных типов поддерживаются различные наборы операторов). В общем, хорош для гео-данных и данных сетевой адресацииSP-GiSTпозволяет организовывать на диске самые разные несбалансированные структуры данных, такие как деревья квадрантов, k-мерные и префиксные деревьяGIN- это “инвертированные” индексы, в которых могут содержаться значения с несколькими ключами, например массивы. Инвертированный индекс содержит отдельный элемент для значения каждого компонента, и может эффективно работать в запросах, проверяющих присутствие определённых значений компонентов. Поддерживает операторы<@,@>,=и&&BRIN(Block Range INdexes, Индексы зон блоков) хранят обобщённые сведения о значениях, находящихся в физически последовательно расположенных блоках таблицы. Для типов данных, имеющих линейный порядок сортировки, записям в индексе соответствуют минимальные и максимальные значения данных в столбце для каждой зоны блоков. Поддерживает операторы<,<=,=,>=и>
Что можно почитать:
Как устроен B-Tree индекс?
Семейство B-Tree (B значит balanced) индексов - это наиболее часто используемый тип индексов, организованных как сбалансированное дерево, упорядоченных ключей. Они поддерживаются практически всеми СУБД как реляционными, так нереляционными, и практически для всех типов данных.